Research and Deployment of AI Agents for Biology
benchmarks.bio
We build verifiable benchmarks that measure how frontier AI agents perform on messy, real-world biological data — across spatial, single-cell, epigenomics, preclinical pharmacology, and biosecurity. Every result is reproducible and published openly.
BioSecBench-Surveillance: A Verifiable Benchmark for AI Agents in Pathogen Genomic Surveillance
Preprint · BioSecBench-Surveillance
BioSecBench-Surveillance is a verifiable benchmark of 100 evaluations testing whether AI agents can infer the right analysis pipeline from raw sequencing data and sparse surveillance context. Each task gives an agent only the data and context a human analyst would have, then grades its structured answer deterministically — spanning seven categories from taxonomic classification to genetic-engineering detection across diverse sample types and sequencing technologies. Across 3,962 gradable attempts from 16 model–harness pairs, the strongest configuration cleared only about half: Claude Opus 4.8 / Pi led at 50.2%, tied with GPT-5.5 / Codex. Built in collaboration with Aclid.
agent.bio
We deploy frontier agents into real scientific work — a public, interactive sandbox already supporting 40+ solution providers and 300+ biopharmas and R&D labs worldwide. Point it at your data, watch it analyze, and put the latest models to work in your lab.
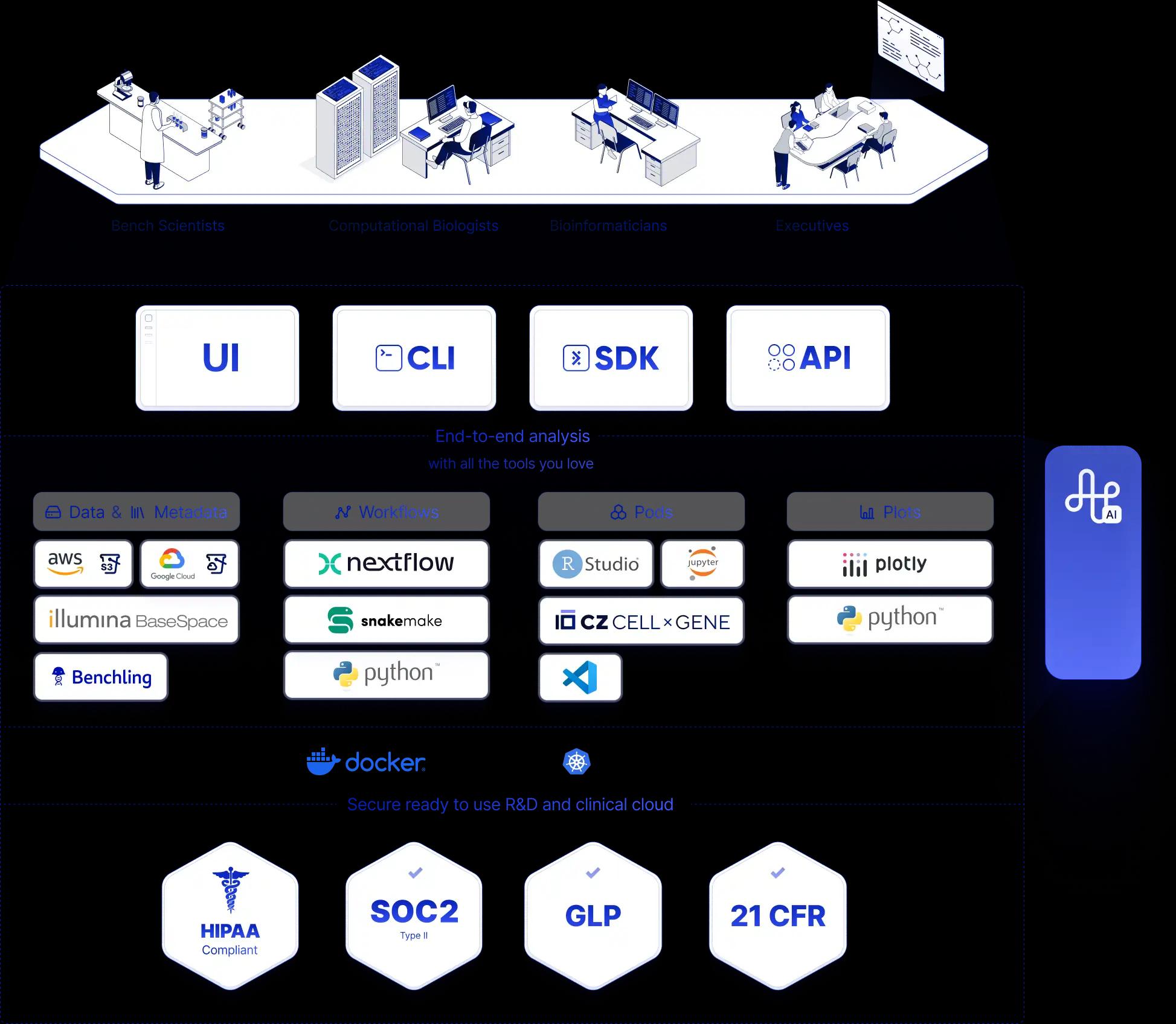
Agent for Solution Providers
Agent for R&D Teams
Book a Call
Put AI to work on the hardest biology data.
- Understand how today's best models handle your data
- Build rigorous benchmarks for real-world biology
- Work directly with our research and engineering team